 ���ں�
���ں�Ӣ�ض���������Aϵ�ж��ԣ���Ⱥ�����Ϸ���ܴ�����������ݴ���Ч�ʷ�������
2022-03-30 23:01:45
- +1 ������
���켫���ʼDZ�Ƶ�����������CES 2022չ����Ӣ�ض������˴���ΪAlchemist��Ӣ�ض������Կ������½�չ�����������ʼDZ���̨ʽ�����ڵij�50���豸���á���2�·�Ӣ�ض�2022Ͷ���ߴ���ϣ�Ӣ�ض��ٴα�ʾARC�����Կ����ƻ�������
3��30��23�㣬Ӣ�ض���ʽ��������������������Կ���ϸ��Ϣ��Ӣ�ض���ʾ������Aϵ�и������ƶ��˶����Կ���������������Ϸ������3ϵ�С�������Ϸ������5ϵ���Լ�Ӳ��������Ϸ������7ϵ�С�

�����Ӣ�ض�����3ϵ���Կ��ıʼDZ��Ѿ���ʼԤ�ۣ���������5/7ϵ�е��ʼDZ���������Ϸ����Ԥ���ڽ����������С�Ӣ�ض�����Aϵ��ȫ������Xe HPG�ܹ����죬����ͨ�üܹ������ܼ�����֧��DX12 Ultimate����ӵ��ǿ���AI�������ǿ��ý�����档Ӣ�ض���Ϊ����Aϵ�д�������һ��Xe��ʾ������µ�ͼ�ι��ߣ������������ֲ�ͬ��ʾ����
��Ȼ�������ƶ��˵IJ�Ʒ���ʼDZ��IJ�Ʒ��̬�Լ�Ӧ�ó�����Ȼ��Ҳ�Ƕ�Ԫ���ġ�Ϊ�����㲻ͬ��Ʒ����Ӣ�ض�����Aϵ��SoC�����ֹ������ACM-G10�����������32��Xe�ں˺�32������Ԫ��16MB L2���棬256bit GDDR6�ӿڣ�16·PCIe 4.0�ӿڡ�ACM-G11�������С��ӵ��8��Xe�ں˺�8������Ԫ��4MB L2���棬96bit�Դ�ӿڣ�8·PCIe 4.0��
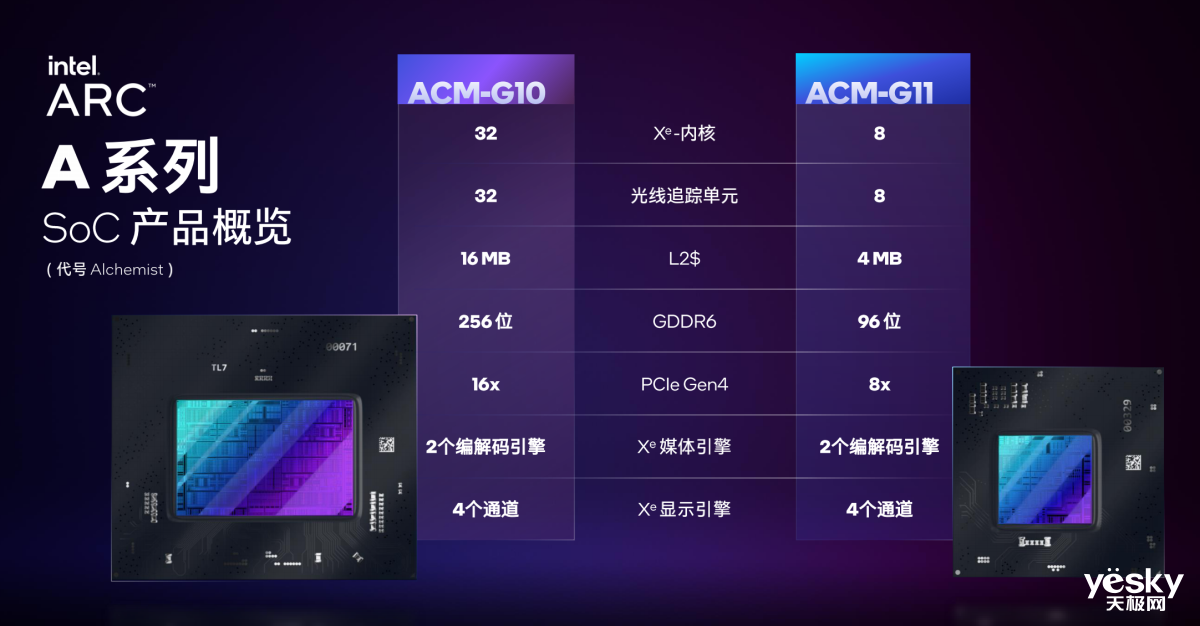
ACM-G10�Լ�ACM-G11оƬ������2��Xe����������4·Xe��ʾ���档
��������Ʒ��ƣ���Ȼ���ƶ��˲�Ʒ�Ͳ��ɱ����Ҫ̸�����ġ�Ӣ�ض���ʾ����Aϵ���Կ�֧��ʵʱ�������ָ�꣬�Ӷ���������ʱ��Ƶ�ʡ����ң������Կ����в�ͬ���أ���ͬһ���صIJ�ͬ�Σ���Ƶ�ʡ�ռ����ָ�궼�Ƕ�̬�ġ�Ӣ�ض�ͨ��ѡ���д����Ը��ؽ��в��Ժ��ƶ��ӽ���ʵӦ�ó�����ƽ��ʱ��Ƶ����Ϊ���������еĶ�������Ӷ��ڿ���TDP�������Ż�ʱ��Ƶ�ʷֲ�������Ч�ܡ�
���ι�������Ʒ���棬����3ϵ�������ƶ��������Կ�����Ҫ�����ᱡ�ͱʼDZ����������е�����5ϵ�С�����7ϵ�н����ǵ���Ϸ����

��������3ϵ�а���A350M��A370M��A350Mӵ��6��Xe�ںˡ�6������Ԫ���Դ�Ϊ64bitλ����4GB GDDR6���Կ�ʱ��Ƶ��1150MHz������Ϊ25-35W��A370Mӵ��8��Xe�ںˡ�8������Ԫ���Դ�ͬ��Ϊ64bitλ����4GB GDDR6���Կ�ʱ��Ƶ��1550MHz������Ϊ35-50W��
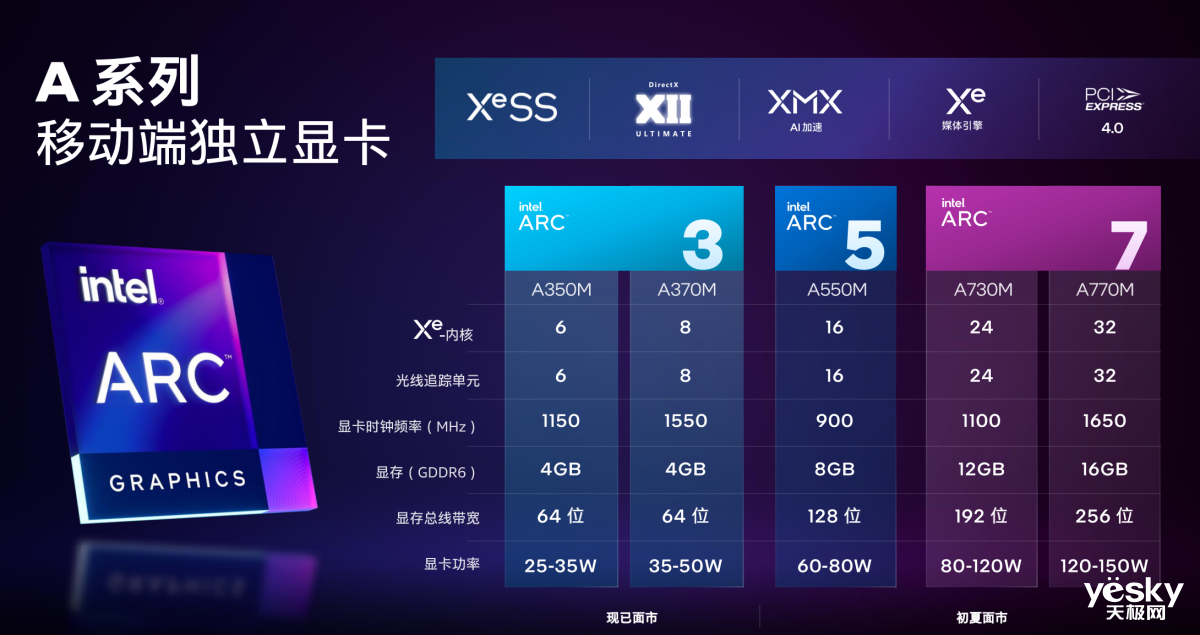
Ӣ�ض��������˽��ڳ������е�����5ϵ�С���A550M������7ϵ�С���A730M��A770M�Ĺ��
ֵ��һ����ǣ�Ӣ�ض�Evo���Ҳ�����䱸���Ŷ����Կ����ڱ�֤Evo��ʱ���ѡ�����������䡢�ɿ����ӵ����Ե�ͬʱ������2������Ϸ����������XeSS��ǿ��Ϸ���顢XMX��ǿ��������ȵ�ȫ�����ơ�

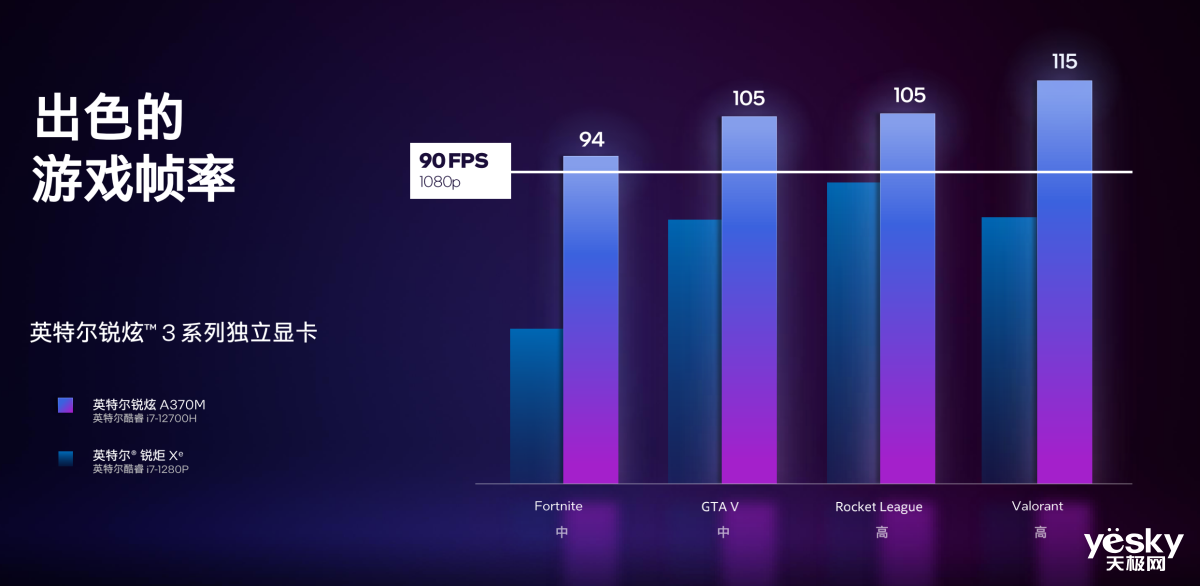
Ӣ�ض�Ҳ������һЩ����3ϵ�ж��Ե����ܱ��֡�����Ϸ�����У�����A370M(�������i7-12700H������)�ܹ����и�����ά��60֡�������С�ɱ��3����������սʿ������ȫ��ս����������������F1 2021�������۹�ʱ��4����������2������Ϸ����ȴ������Xe���Ե�12������ᱡ��������������������

���⣬��һЩ�������Ρ�������Ϸ�У�����A370M���������ṩƽ��֡����90��100���ϵ��������顣�����û����ԣ����Խ���������3ϵ���Կ����ᱡ�������DZȳ����ᱡ�����ܸ�ǿ�ġ�ȫ�ܱ����������Ǵ���������Ϊ�����Ǹ�ǿ������Ϸ���ܣ����ݴ���Ҳ��Ӣ�ض������Կ���һ�����㡣
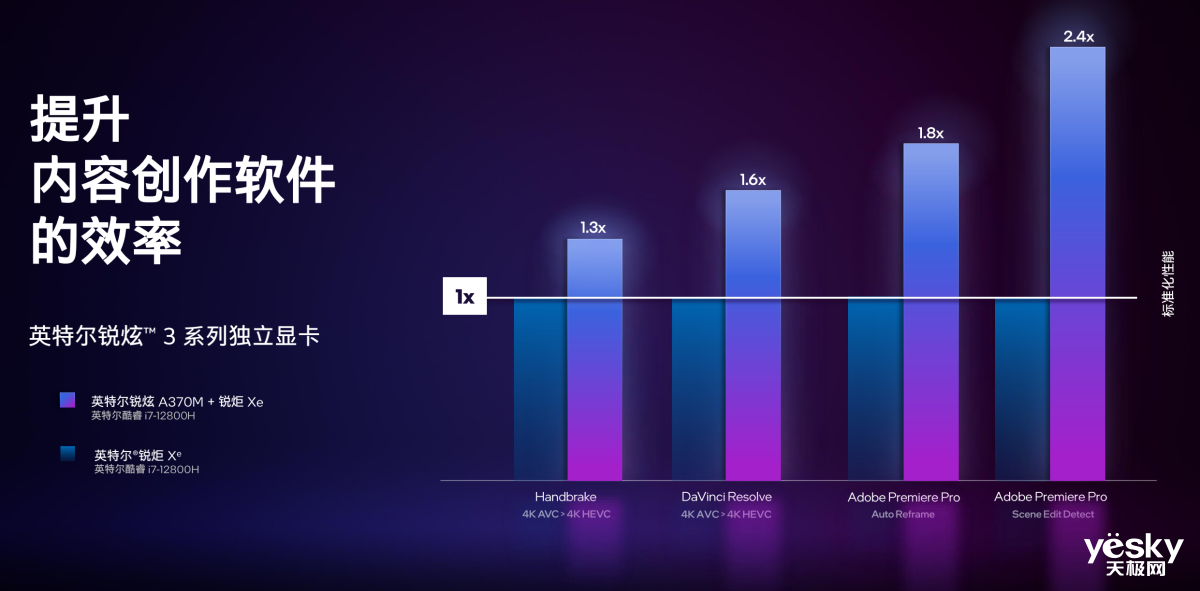
���û�ж��ԵĴ��ؿ��i7-12800H�ıʼDZ����䱸����A370M��HandBrake 4K�������������30%;Davinci Ressolve��4K H.264תH.265���������ɴ�60%;Adobe PR���ݴ���ʱ�����������ǿ��Դﵽ140%����Ȼ��Щ�������������Ŷ��Դ����ģ����벻��ϵͳ��DeepLink�����ӳ֡�
��Ҳ��Ӣ�ض�ѡ�����ȷ�������ʼDZ����ƶ����г���ԭ��֮һ��Ӣ�ض���ʾ��ƽ̨��������Ӣ�ض�һֱ���������ƣ����������������ƣ��ڱʼDZ����ƶ���ƽ̨��Ӣ�ض������ṩ����IJ��컯���ԣ�Ϊ�û��ṩ����ɫ��ʹ�����顣
�����Ҫ�ᵽӢ�ض�Ϊ���Ŷ��Դ�����һϵ��ȫ�����ԡ�
Deep Link
Ӣ�ض�Deep LinkĿǰ������̬���ʹ�������������ͳ�������������Ҫ��������̬���ʹ�������������ϵͳ���ĵ����Ʒ�Χ�ڣ�����������ͷ�CPU��GPU���ܡ�Ҳ����˵����������CPU��GPU�����⡰һ����ƽ��һ����������������֡��������뼼����������Ҫ�����������Ч�ʣ�ͨ��OneVPL��API����ͬʱ�������Ŷ��ԡ������Ե�Ӳ�������������

������������ͬ�������������ݴ���Ч�ʣ�ƾ��Open Vino�е�MLS(����ѧϰ����)��ܰѸ��غ����ķ������ͬ�������棬���ݹ������ص��ӳ����жȡ������������ܵ����ԣ����ܷ��为�ص����ԡ������Լ�CPU��MLS���ڸ������й����в����ɷ�����ֱ���õ����ճɹ���
��Ӣ�ض����ܣ�Deep Link�ܹ�Ϊ���ݴ������٣����ж�̬���ʹ������Դ���30%����������;����������Դ���60%����������;����XMX�ij����������Դ���24%������������
AV1
�����ݴ������棬�����Կ�����һ����Ҫ���ơ������Կ���ý�����������˷dz��㷺�ı������������H.265/HEVC��H.264/MPEG-4/AVC��VP9�ȣ�ͬʱ�����Կ�Ҳ����֧��AV1Ӳ���������ٵ�GPU�����Դ������ݴ���Ч�ʵ��������ݽ��ܣ�AV1��H.264��������߳�50%����HEVC�߳�20%������ܹ��Ը��ʹ�����С�ļ��ṩ���������Ļ��档����AV1����ȫ����û���κ���Ȩ���õı�������������Կ��е�AV1����Ӳ�������봫ͳ����ʵ����ȣ������ٶ������50����Ŀǰ������FFMPEG��Handbrake��Adobe��XSplit���Ѽ����˶�����AV1��֧�֡�

��Ϸ�Ż�
˵�˰������ݴ������������ǻص�����ǹ�ע����Ϸ��
�ڴ�֮ǰ����Ҫ���˽������Կ������ԣ���������ġ�Xe HPG�ܹ�����Xe HPG�ܹ���ÿ4��Xe�ں����һ����Ⱦ��Ƭ����ν��Ⱦ��Ƭ(Rendering Slice)����Ӣ�ض�������IP�Ļ��������顣�������Ⱦ��Ƭ��Xe�ں��ж��䱸���൱������ʸ������XVE����������XMX�����㵥Ԫ�����⣬Xe HPGҲ������ͼ�μ�������������ɫ�������������ȡ�

�ɴ�Ҳ���Կ�����Xe HPG�ܹ�ӵ�к�ǿ������ԣ�Ӣ�ض�����ͨ��������Ⱦ��Ƭ��������ͬ��SoC������������8�����Ӷ���Բ�ͬ��Ʒ���ṩ�ḻ�IJ�Ʒ�����ǰ��Xe LP�ܹ���ȣ�Xe HPGÿ������������1.5����ͬʱ����Ⱦ��Ƭ֧��DX12 Ultimate�����а���������ͼ�ι̶����ܿ�ĸĽ������һ���֧����DXR��Vulkan RT��ר��Ӳ������Ԫ��ÿ����Ƭ���䱸��4��Ӳ����������������֧��ʵʱ�����ټ������ܹ���������3A��������Ϸ������ֺ�ӰЧ����
Xe HPG�ĺ�����Xe�ںˣ���ΪXe HPG�ܹ������ģ�飬ȡ���˴�ǰ�����Կ���EU(ִ�е�Ԫ)��Xe�ں˰���16��256λ����SIMDʸ�����棬Ϊ��ͳͼ����ɫ��ִ�д����㡣ʸ��������Ҫ����ͳͼ�����ļ�����������AI�㷨���ļ�����ȫΧ����һϵ�д��;���˷����ۼ��㷨��Ӣ�ض���ÿ��Xe�ں˹�����ר�þ�������������Ӳ�����١�Xe�ں˰���16���������棬ÿ�����涼��1024λ����

��������רΪ����AI���������ͬʱΪ���������ʸ�������ٵ�Ԫ�ĸߴ�������Ӣ�ض���ÿ��Xe�ں��й�����һ��192KB�Ĵ��ͱ����ڴ��������Ը���ÿ���������ص���Ҫ��L1������������ڴ�(SLM) ֮�䶯̬���䡣
Ӣ�ض������������ͨ��ÿ�����������������˾�����������ƺ�ģ��MAC��ͼ����ʹ�õĻ���SIMDʸ��ָ���ʸ������ĺ��ġ� Xe-HPGִ��8�β�������˷���Ȼ��ִ��8�β��мӷ���ÿ��ʱ���ܹ�16��Ops����;��ǰ�źͺ��ŵķ�����������������µķ�������ۻ���Դ�ͽ����DP4a����Բ���Ҫ32 λ���ȵ�AI�����������Ż�������ԭ���ǽ�����32λ����ֳ�8λ�飬Ȼ������ij�����Щ�飬�ܹ���32�β��г˷�������ɫ������ʾ���� ��������32���ۼӻ�ÿ�������ܹ�64�β������ȱ�SIMD MAC���������4��������������ͨ�����˷��ۼ�4�����ˮ��������������һ���µ�ˮƽ�� ��DP4aһ����ÿ�������������ֳ�4���飬��Щ�鱻��������˺��ۼӡ���ÿ����64������������ɫͼ����ʾ���� ͨ��4���Σ�ÿ��ʱ�Ӳ���256�β������ȴ�ͳ��32λSIMD MAC����������16������

̸��ʸ�����棬Ӣ�ض�Ϊ�˸���������(FP)�ṩר��ִ�ж˿ڣ���ALU(��������Ԫ)�����˸Ľ���FPָ�����ڿ�������������(INT)ָ��ͬʱ���У����а���DP4a�Ŀ���INT8���㡣ͬʱӢ�ض���ǿ����AI�������������µ�XMX�����������ڸ�����������˷������������AI�������ͣ�����BF16��INT8��

Ϊ����Ч���ִ�����ܺ�������Xe-HPG����ͬʱ���Ⱥ�ִ�и���FP������INT��XMXָ�����������ʽ�����������������Դ��

��ôʸ�����桢�������涼��ʲô�ã�����һ����Ҷ�����Ϥ��Ӣ�ض�������������XeSS�����������һ����ҪӦ������ʵʱ��Ⱦ�����е���AI���ɴ�Ӣ�ض��Ƴ���XeSS����NVIDIA��DLSS�е����ƣ�ʹ�������縨���˶�ʸ�����ӵͷֱ�����Ⱦ�����ɸ߷ֱ���ͼ������XeSS�����������ֱ��ʵ�ͬʱ����֤���ߵ����ܣ�������Ϸ���١����磬����Ϸ�ܹ���ԭ��1080p�ֱ��ʵ�������Ⱦ��Ϸ֡��Ȼ��ͨ��XeSSʵ�ֽӽ�ԭ��4K�ֱ��ʵĻ��ʡ�

Ŀǰ��֧��XeSS����Ϸ�ܼ���14�δ�����»����и�����Ϸʵ�ֶ�XeSS��֧�֡�
��������Ϸ���鷽�棬�����Կ�����֧��Adaptive Sync������Ӣ�ض����Ƴ���ȫ�µ�Speed Sync��Smooth Sync�����������������κ���ʾ���������ͬ���⣬������ʾ������Ϸ����ˢ���ʲ�ͬ�����ӳ����ӵȵȡ�Speed Syncͨ���ر�V-Sync�����ƻ��治ͬ�������⣬ʼ����ʾ���һ����Ⱦ֡�����壬������˺�ѡ�Smooth Sync����ͨ������ģ��������˺��֮֡��ı߽��������Ӿ�ʧ�棬���V-Sync�ѹرպ���Ⱦ����������ˢ�����ڲ�ͬ�������⡣

�ڷ�������Aϵ���Կ���Ʒ��ͬʱ��Ӣ�ض�Ҳ�Ƴ���ȫ�������Կ�������塪��ARC Control���û������¼�Ϳ���ͨ��ARC Control����Կ��������������鿴�Կ����ܸ���(����̨ʽ������֧�����ܵ���)����������ͷ�趨���Զ�������Ϸ�߹�ʱ�̡��ṩ���õ�ֱ�������Լ�������صĹ��ܺ����á�ARC Control�����ṩ���ܼ��ܣ����Ծ���IJ����Ϳ��ӻ�ͼ���ṩ���û��ο���Ŀǰ��ARC Control�Ѿ��������أ��������Կ���Ҳ֧��Ӣ�ض������ԡ����⣬�������͵�������Կ���ARC Control���Զ����·���ʱ�ջ��µ���Ϸ��������Ϣ��

����
��Ȼ���ػض����г�����������Ӣ�ض����Կ�����Ҳ�в��֣�ͨ����ǰ�����������ԣ��Ѿ����ֳ�Ӣ�ض�����ƽ̨�����ƣ�ͨ�������Կ�������ʹ�����������������ô��������Ե��ᱡ���ṩ���ż���Ϸ���顣������һ�η����߶˵����Ŷ��ԣ�Ӣ�ض���ν�ǡ��������ڡ���ƾ����ڡ�˫i���İѿأ�Ӣ�ض��ڼ�����������������Ӣ�ض�����Ϸ�����ߡ����������ߵ���̬������Ⱥ����������Ŷ�������������Ϸ���ܣ����������ݴ���Ч�ʶ��൱ֵ���ڴ���
Ӣ�ض������Կ�����Ϊ�Կ��г��ġ����㡱����������Ŀ�Դ��ɡ�











��־ΰ
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼

































